Transcription API Comparison: Google Speech-to-text, Amazon, Rev.ai
In this post I will be comparing Google Cloud speech-to-text, Amazon Transcribe and Rev.ai, three of the most popular speech-to-text services available today.
Automatic speech recognition (ASR) has always been a difficult problem for computers not only because humans all speak so differently but because there’s an infinite number of variables that come into play including sound quality, background noise, intonation, accents, filler words, laughter, etc. For most of us, we simply don’t speak the way we write so asking a computer to guess what that speech might be in writing is actually a remarkable task.
I tested the 3 services mentioned and compared them for factors such as accuracy, pricing, functionality, features & customizability. We will cover:
- Test results showing which API was the most accurate
- Visual data of WER and accuracy scores for each service
- Sample transcripts generated by the different APIs
- Comparison table of all features
Features & Functionality
- Languages: Google supports over 125 languages and variants, whereas Amazon Transcribe supports about 30 different languages and variants. Rev.ai currently only supports English, but this automatically includes variants of english (e.g UK vs. US).
Custom Vocabulary, Speech adaptation: All 3 services allow you to specify a custom vocabulary list which aids in the transcription of technical or domain-specific words/phrases as well as the spelling of names and other special words. Google and Amazon go a step further by offering several extra options that make this feature more flexible and powerful.
Google lets you specify contexts with fields like phone number, address, currency, and dates to help with formatting those values (for example transcribing the words twenty twenty as 2020)
Amazon transcribe not only lets you specify the custom vocabulary to expect, but how it should be formatted in the transcript and what it will sound like. This can be especially useful for names of people or places that are not necessarily spelled the way they are pronounced.- Content redacting and filtering: All 3 API offer the option of automatically filtering out profanity or inappropriate words from the transcription. In addition, Amazon also has the option to filter out personally Identifiable information (PII). This can be extremely helpful when transcribing audio with sensitive data such as certain customer service conversations or recordings in the medical field.
Multichannel recognition & Speaker Diarization: This is the ability for ASR to distinguish when there are different sources of audio ( e.g Zoom conference call) or in the case of speaker diarization, to determine which speaker in the audio is saying what when there are multiple speakers. All 3 services offer this feature, which in turn allows them to generate time-stamped transcripts separated by speaker/channel.
Punctuation: Although for Google this feature is only available in Beta, all 3 APIs have the ability to automatically add punctuation to transcribed text. As one can imagine, this is a daunting task, because punctuation is sometimes subjective/ambiguous and even humans can listen to the same audio and punctuate it slightly differently.
Models: Google has a few different models for different use cases: phone call, video, command and default. For my testing I used the video model because it seemed to be the most accurate one of the bunch, even though it’s a little bit more expensive than their default model. Amazon has a default model (which I used) and a niche medical model.
Pricing
This is subject to change but at the time of writing:
- Google Cloud Speech-to-Text (video model) is $0.036 per minute of audio, charged in 15-second increments, rounded up. (Google does offer standard models which are cheaper at $0.024 but the accuracy was not nearly as good as their video model used in our tests.)
- Amazon Transcribe charges for a minimum of 15 seconds per job but otherwise charges by the second at a price of only $0.024/minute, making it the cheapest option.
- Rev.ai costs $0.035/min and charges in 15-second increments, rounded up. They also have special pricing of $1.20/hr for larger volume commitments.
Transcription API Comparison Table
| Features | Amazon | Rev.ai | |
|---|---|---|---|
|
Languages+variants |
125+ |
30+ |
English + variants |
|
Supported media |
FLAC, WAV, OGG,
MP3 (beta), AMR |
WAV, MP3, MP4 and FLAC |
All common audio & video formats |
|
Custom Vocabulary |
|
|
|
|
Content Filtering |
|
|
|
|
Channel Detection |
|
|
|
|
Speaker Diarization |
Beta |
|
|
|
Punctuation |
Beta |
|
|
|
Auto-detect language |
|
|
|
|
Real-time streaming ASR |
|
|
|
|
Models |
phone call, video, command, default |
default, medical |
default |
|
SDK |
C#, Go, Java, Node.js, PHP, Python, Ruby |
.NET, Go, Java, Javascript, PHP, Python, Ruby |
Java, Node.js, Python |
|
Pricing |
$0.036/min = $2.16/hr |
$0.024/min = $1.44/hr |
$0.035/min = $2.10/hr
($1.20/hr for larger volume commitments) |
|
Max media length |
4 hrs |
4 hrs |
17 hrs |
|
User Interface for creating transcripts |
1-min audio only |
|
|
Which Speech-toText API was the most accurate?
For running these tests, I chose episodes from 3 podcasts of varying styles/formats.
- 99% Invisible: Age of the algorithm – mix of formal, pre-written text read aloud by host + interviews and quotes from other speakers
- Screaming in the Cloud: Kubernetes – multi-speaker casual conversational interview ( 2 speakers)
- So Money: Ask Farnoosh/Q&A – single speaker; conversational
Measuring the accuracy of transcribed text generated by automatic speech recognition is a challenging task because different errors tend to affect readability and usability in different ways. Simply tallying errors isn’t enough as some errors can completely alter the intended meaning whereas other errors might leave the meaning in tact and have very little effect. Therefore, I decided to use 2 different methods that hopefully compliment each other to give us better insight into accuracy:
1. Word Error Rate (WER)
The Word Error Rate (WER) is the most commonly used metric for evaluating the accuracy of transcripts generated by Automatic speech recognition models and is calculated as follows:
WER = (Substitutions + Insertions + Deletions) / number of Words Spoken
Lower WER values suggest higher accuracy. The score represents how often an error occurred in a given transcript. For example, for audio with 1000 words, a 5% Word error rate means that there were errors with about 50 words , or on average about one error for every 20 words.
I used the JiWER Python package to calculate WER values. I also used this package to perform some basic normalization of the text such as removal of punctuation and letter capitalizations prior to calculating the scores.
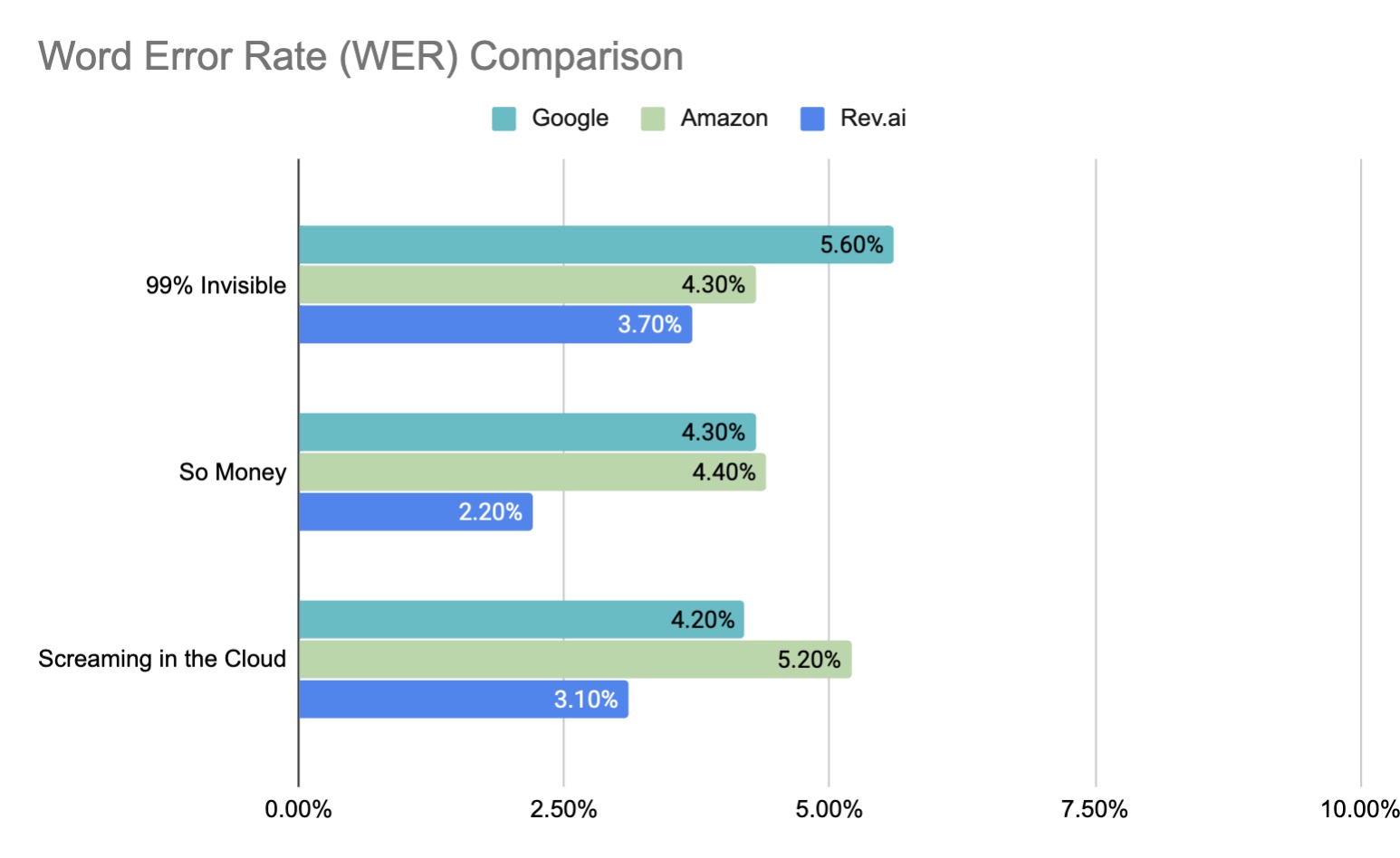
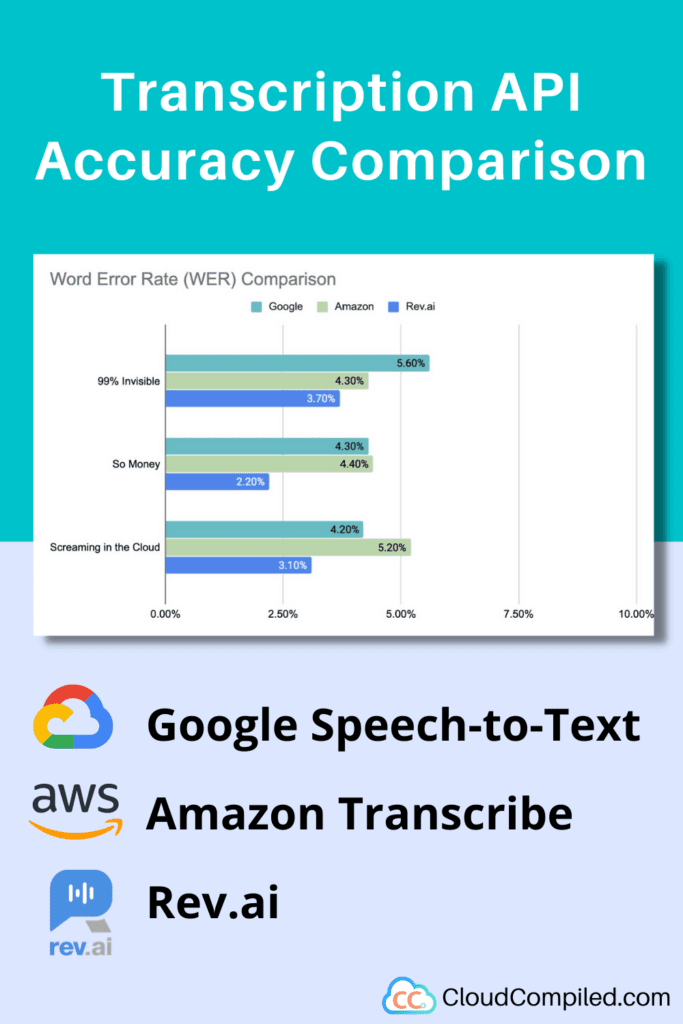
- Average WER scores across all 3 episodes:
- Google – 4.7%
- Amazon – 4.63%
- Rev.ai- 3.0%
- Rev.ai had the lowest WER for each episode while Amazon and Google flip-flopped between second and third place depending on the episode.
While WER numbers offer some insight into accuracy, it’s also a limited metric because it treats all errors equally. For example, “bat” transcribed incorrectly as “brat” and “cast” transcribed as “casts” would both be counted as equal mistakes. However, while cast and casts are versions of the same word and are unlikely to affect usability of the transcription, bat and brat are completely different words and therefore have the potential to alter the original meaning of the spoken audio.
In addition, WER calculations do not take into account punctuation or proper letter casing since these are removed prior to calculations. Therefore, these measurements should be treated as an insight, rather than a full picture on accuracy.
2. Checking text similarity
The second method I used for measuring accuracy was to check text similarity. The idea here is that rather than counting the number of errors, you check how similar the transcribed text is from the original transcript, using a certain criteria.
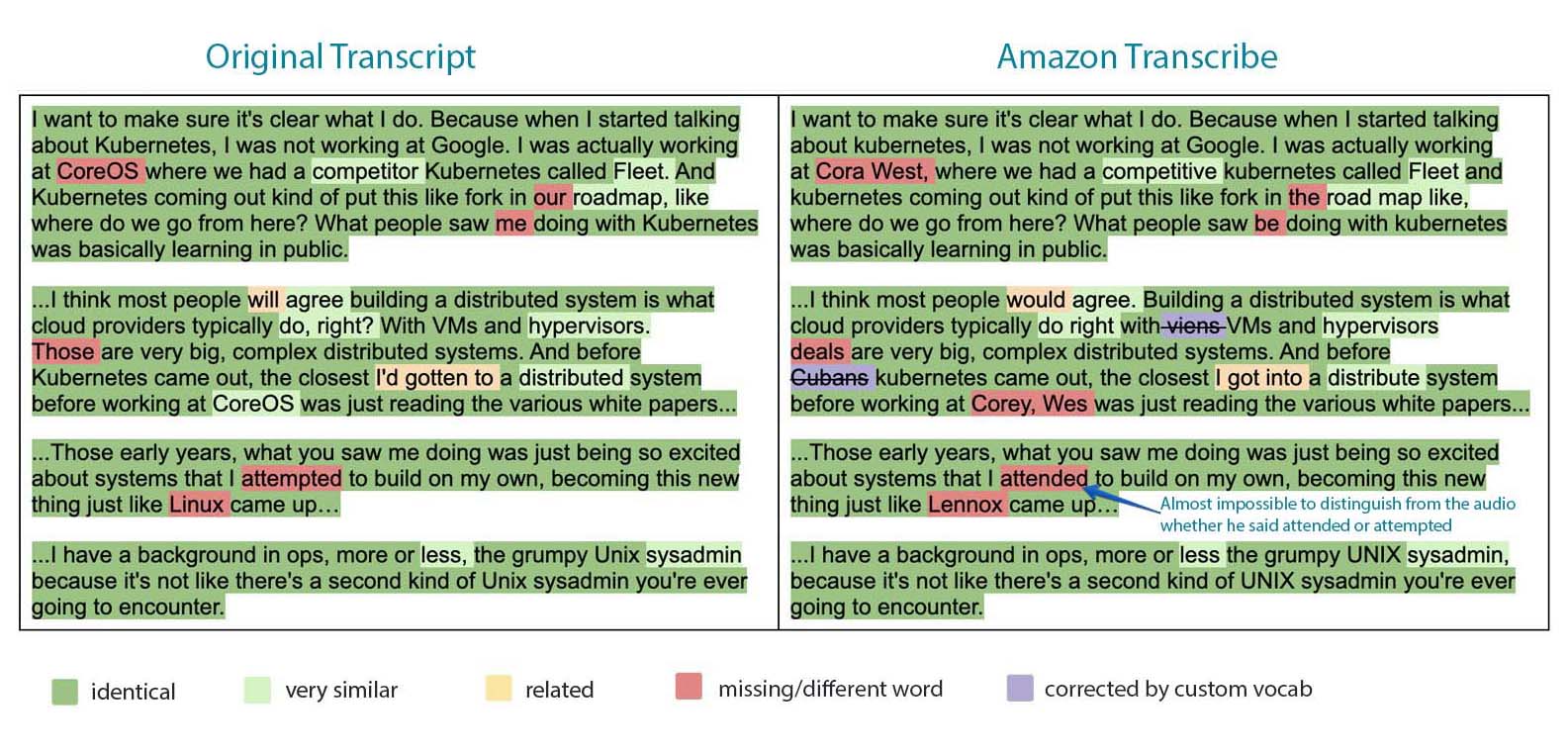
To do this I decided to use a paid API that analyses 2 text sources and uses AI/ML to output a similarity score. These kinds of API are often used in plagiarism detection software. This particular API that I used compares the 2 text sources and tells you which parts of the text were classified as identical, slightly different, related meaning or omitted. (Examples shown below). The labels were not always perfectly assigned for every single word but for the most part it did a very decent job of categorizing correctly. The advantage of using this method is that it doesn’t ignore punctuation/case and all mistakes are not categorized equally so it provides more information about the performance of each service.
Below are examples showing the original transcript vs. generated transcript for each service, highlighted based on the following categorizations:
- Identical – Exactly the same, including punctuation and letter case
- Very Similar – Almost identical but different punctuation, case, same root word but different tense, singular vs. plural, etc.
- Related – Slightly different words but similar meaning (e.g will vs. would or gonna vs. going to)
- Missing/different word – wrongly transcribed as a different word, or missing.
- Corrected by custom vocabulary – words that were transcribed incorrectly at first but were transcribed correctly in a subsequent run after a vocabulary list was given. (I manually added these to the transcripts afterwards to show the “before & after” of supplying a vocabulary list.)

Observations / Comparison
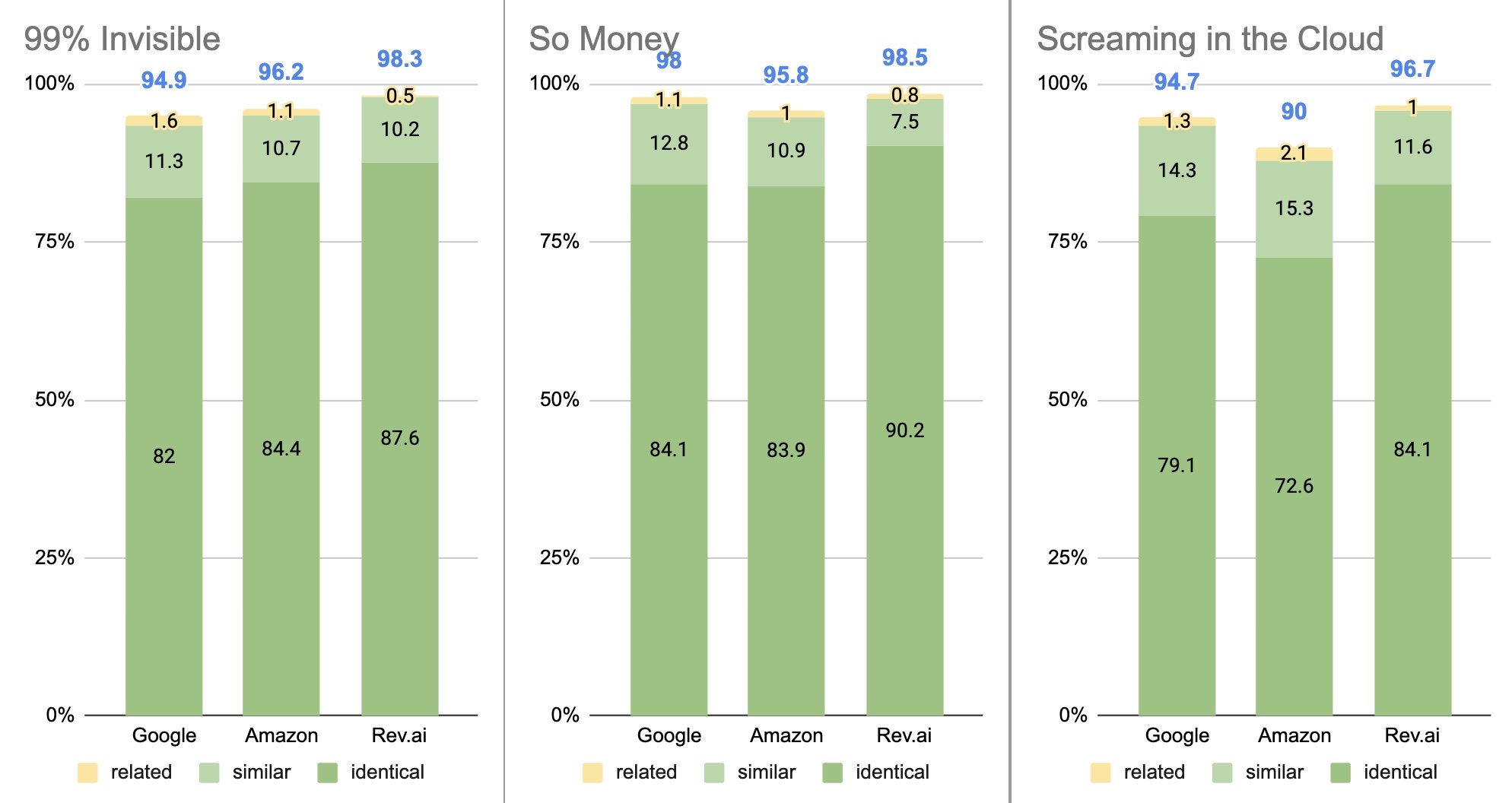
- Average similarity/accuracy score across all 3 episodes:
Google – 95.87%
Amazon – 94%
Rev.ai – 97.83% - Rev.ai was the most accurate and produced the most grammatically correct/polished transcript. It seemed to be able to take context/overall grammar correctness into consideration to help it write better sentences.
- Google was vey good at transcribing technical terms, even without being provided a vocabulary list. However, giving it a vocabulary did not seem to improve it further. For example, both Amazon and Google transcribed the term VM incorrectly at first. After supplying a vocabulary list, Amazon was able to get it right but Google continued to transcribe it incorrectly even with the list.
- Amazon and Rev.ai both did a pretty decent job of adding punctuation. In comparison, Google (whose punctuation feature is technically still in Beta) struggled with this and sometimes added punctuation in odd places, as shown in one of the screenshots above.
- All 3 services had their lowest similarity /accuracy score for the “Screaming in the cloud” podcast. This is likely because that episode was the most free-form and conversational out of all 3, which can make punctuation and construction of exact sentences more difficult. It was also the one with the most technical terms. (Note that accuracy scores shown are for transcripts generated without using a vocabulary list)
Conclusion
So which transcription service should you use? It really depends on your use case but here’s what I can say based on my tests and research:
- Rev.ai was the most accurate. If accuracy is the most important factor and you need transcripts that are as close to end-user ready as possible, Rev.ai is the way to go. In all the tests, their transcripts were the most polished and closest to what you would expect from a human transcriber. They also have a user friendly interface if you want to transcribe audio without implementing the API.
- Amazon Transcribe was by far the most cost-effective by a fairly significant margin while still producing good accuracy. If pricing is an important factor and you are planning to transcribe high volumes Amazon would be the option of choice. (Google does offer a default model which has comparable pricing but it’s not as accurate as the video model which was used for these comparisons)
- If you will be transcribing audio with many technical terms and cannot supply a vocabulary list, Google Speech-to-text (Video Model) is likely to do the best job.
- This should go without saying but if you are after a certain feature available to one and not the other, then you should decide based on the feature set you need. See feature comparison table
Caveats, etc
- Three episodes is not a large enough sample size to really calculate proper average scores. Therefore these test scores are meant to be used to compare the 3 services against each other, rather than as absolute scores.
- In order to limit the number of variables for these tests, I did not focus on the effect of audio quality . i.e, all of the audio used for my tests were of decent quality
- Although Google has a few different speech-to-text models, I decided to use their video model because when I tested, it was a little bit more accurate than the default model even though it’s a little bit more expensive. I thought it would make for the most interesting comparison to compare each service at its best.
- I did not touch on accuracy of diarization (identifying which speakers said what). However, from observing generated transcripts, Amazon and Rev.ai seemed to perform better in this area than Google (whose diarization feature is still in Beta)
- Tests mentioned in this article were done in June 2020. Since all 3 services are constantly updating their models it’s possible that features and scores may differ in the future.
The pricing you list for Rev is the pay as you go rate for low volume users. Rev.ai has enterprise pricing which is HIGHLY competitive at scale, starting at not crazy high volumes. It would be great if you would correct this inaccuracy.
Hi Ellen,
I have updated the pricing table to note this. As stated in the caveats section, this data was compiled in June 2020 and is subject to change. At the time of writing this article Rev had no enterprise pricing displayed publicly. Although there’s a price now, it’s still not clear what your required commitments are to receive the enterprise pricing. Feel free to leave a comment with specifics about your pricing at Rev for users who might be interested. Thanks.
I saw your article on LinkedIn. I have developed an Introduce Yourself PROnunciation script, of 148 words and 854 characters, for use with my American accent pronunciation clients. It is phonetically sensitive to 100% of the spoken consonants, vowels, unique American sound variations, -ed, and -s endings, Y and W insertions, spoken: “the”, “a” & “to” and linking variations. Also, the majority of clusters/blends. My clients call google voice to record the script. I color annotate the transcription (very similar to what you did) while listening 3 times. The learners are very engaged in this repeated task and evidence great gains in this potent, meaningful, high-impact practice. As a proven tool, I wonder if there is an interest in its use? I can’t see the author’s name. Please contact me.
Use Azure ASR. You have more language, higher accuracy and cheaper price(no stupid rounding up).
Hi great article! I wanted to find out which API you used to find and analyze the similarity between the texts, as I would like to use something like this for my project that I’m doing.
What is the API that you used to find the similarity score between the transcription software and the original transcript. I would like to use it for a research that I’m conducting. Would be very grateful.
Nice article, interested to see you are using a text analysis to asses the accuracy. Which API did you use for this analysis?
Hi there! Great post and analysis, Truly educational, can you give more context on point 2? Checking text similarity? I’d love to hear your approach to the text similarity and which method you used to compare the manual and automated transcripts.
Thanks!!